Microsoft has announced a bunch of new features for Microsoft 365 Copilot, its AI-powered work assistant. These features include a new task tool built on Anthropic’s Claude technology, a smarter research feature that pits multiple AI models against each other for better results and a side-by-side model comparison tool that lets users see how different AIs approach the same question.
The updates, part of what Microsoft is calling Wave 3 of Microsoft 365 Copilot, are available now through the company’s early access Frontier programme, the company announced.
Copilot Cowork: Delegate work, not just tasks
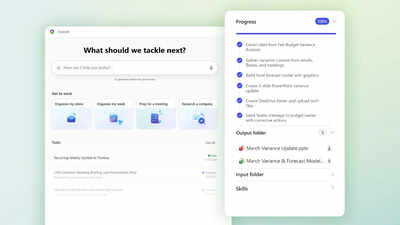
The headline feature is Copilot Cowork – a tool designed for work that unfolds over time, rather than simple one-off prompts, the company suggests. Copilot Cowork is built to take on multi-step work autonomously. A user describes the outcome they want, and Cowork creates a plan, works across the relevant tools and files, and carries the work forward, meanwhile, showing its progress, allowing the user to step in and steer at any point.
The feature is built on the same technology platform that powers Anthropic’s Claude Cowork, and comes with built-in skills from both Claude and Microsoft.
Researcher gets smarter with a built-in critic
Microsoft’s Researcher feature, which helps users tackle complex questions by pulling together information from multiple sources, has also been upgraded with a notable new capability: a Critique function that uses two AI models instead of one.
“Introducing Critique, a new multi-model deep research system in M365 Copilot. You can use multiple models together to generate optimal responses and reports,” said Microsoft CEO Satya Nadella, adding that “Benchmarks show this delivers best-in-class deep research!”
In this setup, one model plans the task and produces an initial draft. A second model acts as an expert reviewer, and scrutinises and refines the output before the final response is delivered. The two models are drawn from frontier AI labs including Anthropic and OpenAI.
Microsoft says Researcher with Critique now scores 13.8% higher on the DRACO benchmark – the industry standard for evaluating deep research quality, measuring accuracy, completeness and objectivity.
Model Council: Multiple AI perspectives
Also new is a feature called Model Council, which allows users to compare responses from different AI models on the same question simultaneously. Users can instantly see where the models agree, where they diverge, and what each one brings to the table that the others do not. Microsoft describes it as having multiple researchers available at once.


{kind=link}